Speeding up page loads with secondary indexes
Jacob O'Bryant | 31 Aug 2024
Continuing my previous work on using XTDB's secondary indices to handle derived data, I've started using them to re-implement various parts of Yakread. I started with the subscriptions page. This shows a list of all newsletters and RSS feeds you've subscribed to. It sorts them based on when the most recent post was published and it tells you how many unread posts there are.
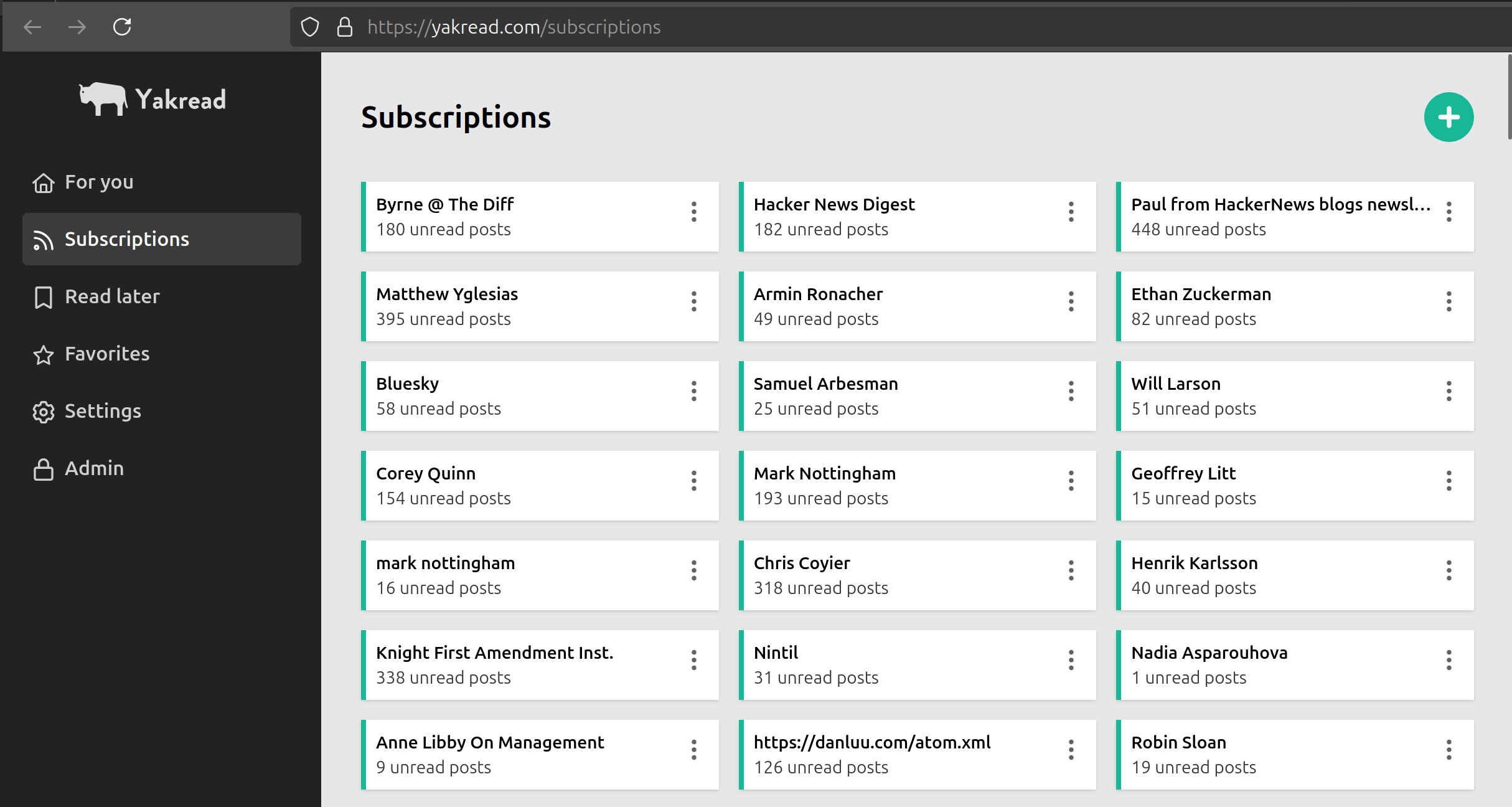
I originally implemented this by simply querying for each post and counting how many are unread etc. each time you load the page. As such, it's slow as molasses: the page takes 13 seconds to load for my account. A more traditional approach to make this faster would probably be to update various parts of the codebase so that they keep track of all the derived data we need. Each subscription could have a field for the number of unread posts which would be incremented/decremented whenever you open a post or mark it as unread. And so on.
With Biff's not-yet-released indexes feature, I've instead written an "indexer function" which takes in transactions from XTDB's transaction log and uses them to build up a second database of derived data. Like event sourcing. The indexer code is pretty convoluted, but hopefully it's still a better experience than having to spread the logic out across your whole codebase. And the result is marvelous: loading all my subscription data takes only 100ms - 150ms now, a 100x improvement. I should be able to further reduce the query time with some more updates I've got planned.
"Updates" might actually be a bit of an understatement: as nice as this first step went, I need to redo the whole feature. Currently the secondary indexes are also stored in XTDB—so you have your main XTDB instance, and then another XTDB instance (using filesystem persistence) for each secondary index you define. As I've started to make additional indexes for Yakread, I've hit a problem with that approach.
Whenever you update a document in XTDB, the entire new document is added to the doc store. e.g. if you have {:xt/id 1, :message "hello"} and then you update it to {:xt/id 1, :message "how do you do"}, the doc store will retain both
versions of the document, without structural sharing. If the document grows large and you make lots of small updates to
it, that could start taking up a lot of disk space.
Normally that's not a big deal because you can just model your data in a way that doesn't involve accumulating a bunch
of gigantic documents. For example, when Yakread checks an RSS feed for new posts, it creates a document that looks like
{:xt/id #uuid "...", :post/url "https://example.com/my-post", :post/rss-feed "https://example.com/rss", ...}. If you
want to get a 1 -> n mapping for a particular RSS feed, you just query for all the documents that have :post/rss-feed "https://example.com/rss".
The problem for Biff's secondary indexes is that queries are slower then looking up a single document, and we really
need these indexer functions to be fast. Otherwise they'll bottleneck your app's write throughput. So as a rule,
indexer functions only do xt/entity calls (i.e. they only look up documents by their primary key), they don't do any
xt/q queries. Which, you know, is kind of a problem when you need to be able to ask "what posts are part of this RSS
feed" since some feeds can have thousands of posts. I don't want to have a single RSS feed document with thousands of
references to other documents, all of which would have to be duplicated on disk every time the feed publishes another
post.
Hence, I've just barely started to re-implement the entire index feature by using RocksDB directly for the secondary indexes. RocksDB is a mutable KV store, so we can update documents in place without retaining the history—a useful feature for our main source-of-truth database; less critical for these indexes. RocksDB does support in-memory snapshots, which means Biff can still give you a consistent view over your main XT database and your secondary indexes.